

-


编程语言
站-
热门城市 全国站>
-
其他省市
-
-

 15692118659
15692118659
 小标
2018-06-20
来源 :
阅读 1146
评论 0
小标
2018-06-20
来源 :
阅读 1146
评论 0
摘要:Python语言在文本处理方面是很强大的,得益于有re这样强大的模块,re模块是用于处理文本的超级强大的工具,当然了,其他语言可能也提供了正则表达式的模块,但是个人感觉python的re模块做的是非常好的,希望对大家学习Python语言有所帮助。
Python语言在文本处理方面是很强大的,得益于有re这样强大的模块,re模块是用于处理文本的超级强大的工具,当然了,其他语言可能也提供了正则表达式的模块,但是个人感觉python的re模块做的是非常好的,希望对大家学习Python语言有所帮助。
当然了,外行会问了,正则表达式是做什么的呀?听起来玄乎其神的,说白了就是,给你一个很大的文本文件,让你在里面找符合一定规律的语句,你怎么找呢?比如让你找一个这样的语句:ABCDabcd,你也许会说直接用str类的查找就好了,好,那我问你如果让你查找一个这样的呢ABCD???abcd,其中的问号表示任意的一个数字,也就是(ABCD三个数字abcd)这样的形式呢?难倒你了吧,哈哈哈,现在使用正则表达式处理这样的问题就妥妥的啦
简单介绍一下,使用正则表达式的流程:
A, 初始化一个正则表达式引擎
B, 使用这个引擎在给定的文本里面查找符合条件的结果
先来看一下re模块的语法吧,见下图:
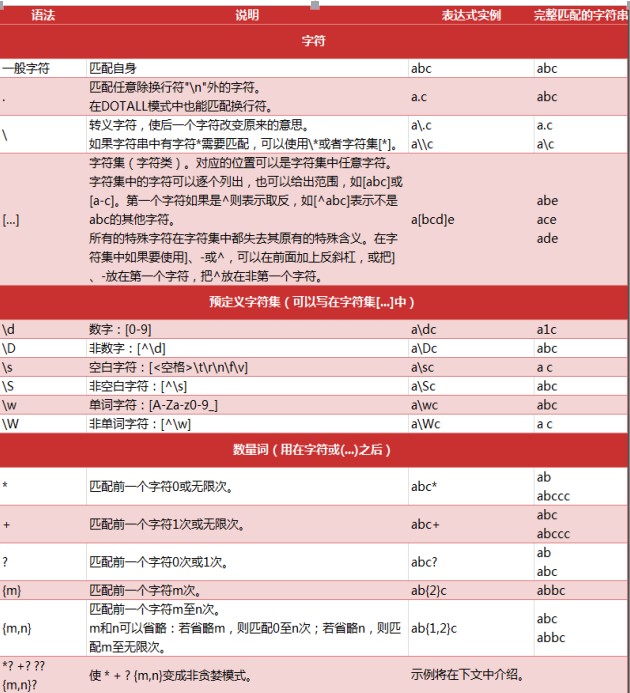
re中的函数:
re.compile(pattern, flags=0)
返回一个正则表达式对象,下面两种写法的作用是等价的:
写法1:
prog = re.compile(pattern)
result = prog.match(string)
写法2:
result = re.match(pattern, string)
re.match(pattern, string, flags=0)
从string的开头进行匹配,如果开头没有匹配成功,则返回None,如果匹配成功,返回且仅仅返回第一个match object(一会再介绍match object的用法)
re.search(pattern, string, flags=0)
扫描整个string,如果没有匹配,返回None,否则仅仅返回第一个成功匹配的matchobject
re.split(pattern, string, maxsplit=0, flags=0)
通过正则表达式将字符串分离。如果用括号将正则表达式括起来,那么匹配的字符串也会被列入到list中返回。maxsplit是分离的次数,maxsplit=1分离一次,默认为0,不限制次数。
示例:
>>> re.split('\W+', 'Words, words, words.')
['Words', 'words', 'words', '']
>>> re.split('(\W+)', 'Words, words, words.')
['Words', ', ', 'words', ', ', 'words', '.', '']
>>> re.split('\W+', 'Words, words, words.', 1)
['Words', 'words, words.']
>>> re.split('[a-f]+', '0a3B9', flags=re.IGNORECASE)
['0', '3', '9']
也许你可能看起来比较吃力,提示一下:\W表示非单词字符,+号表示匹配前一个字符1次或多次,这样理解起来就容易一些了吧,还有,如果在字符串的开始或结尾就匹配,返回的list将会以空串开始或结尾,如果字符串不能匹配,将会返回整个字符串的list。
re.findall(pattern, string, flags=0)
找到RE 匹配的所有子串,并把它们作为一个列表返回。这个匹配是从左到右有序地返回。如果无匹配,返回空列表(个人觉得这个函数是最常用的)
re.finditer(pattern, string, flags=0)
搜索string,返回一个顺序访问每个匹配结果(matchobject)的迭代器
示例:
import re
p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print(m.group(),end=’’)
### output ###
# 1 2 3 4
re.sub(pattern, repl, string, count=0, flags=0)
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
re.subn(pattern, repl, string, count=0, flags=0)
实现的功能跟sub()函数是一样的,但是返回的结果是(new_string,number_of_subs_made)
match object:
匹配对象,这个是match(),search(),finditer()函数返回的值。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
本文由职坐标整理并发布,了解更多内容,请关注职坐标编程语言Python频道!
 喜欢 | 1
喜欢 | 1
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-IT技术咨询与就业发展一体化服务 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




