

-


编程语言
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 小标
2018-07-16
来源 :
阅读 866
评论 0
小标
2018-07-16
来源 :
阅读 866
评论 0
摘要:本文主要向大家介绍了Python语言3 是如何解决棘手的字符编码问题的,通过具体的内容向大家展示,希望对大家学习Python语言有所帮助。
本文主要向大家介绍了Python语言3 是如何解决棘手的字符编码问题的,通过具体的内容向大家展示,希望对大家学习Python语言有所帮助。
Python3 最重要的一项改进之一就是解决了 Python2 中字符串与字符编码遗留下来的这个大坑。Python 编码为什么那么蛋疼?已经介绍过 Python2 字符串设计上的一些缺陷:
· 使用 ASCII 码作为默认编码方式,对中文处理很不友好。
· 把字符串的牵强地分为 unicode 和 str 两种类型,误导开发者
当然这并不算 Bug,只要处理的时候多留心也可以避免这些坑。但在 Python3 两个问题都很好的解决了。
首先,Python3 把系统默认编码设置为 UTF-8
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
>>>
然后,文本字符和二进制数据区分得更清晰,分别用 str 和 bytes 表示。文本字符全部用 str 类型表示,str 能表示 Unicode 字符集中所有字符,而二进制字节数据用一种全新的数据类型,用 bytes 来表示。
str
>>> a = "a"
>>> a
'a'
>>> type(a)
<class 'str'>
>>> b = "禅"
>>> b
'禅'
>>> type(b)
<class 'str'>
bytes
Python3 中,在字符引号前加‘b’,明确表示这是一个 bytes 类型的对象,实际上它就是一组二进制字节序列组成的数据,bytes 类型可以是 ASCII范围内的字符和其它十六进制形式的字符数据,但不能用中文等非ASCII字符表示。
>>> c = b'a'
>>> c
b'a'
>>> type(c)
class 'bytes'>
>>> d = b'\xe7\xa6\x85'
>>> d
b'\xe7\xa6\x85'
>>> type(d)
class 'bytes'>
>>>
>>> e = b'禅'
File "", line 1
SyntaxError: bytes can only contain ASCII literal characters.
bytes 类型提供的操作和 str 一样,支持分片、索引、基本数值运算等操作。但是 str 与 bytes 类型的数据不能执行 + 操作,尽管在py2中是可行的。
>>> c = b'a'
>>> c
b'a'
>>> type(c)
<class 'bytes'>
>>> d = b'\xe7\xa6\x85'
>>> d
b'\xe7\xa6\x85'
>>> type(d)
<class 'bytes'>
>>>
>>> e = b'禅'
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
encode 与 decode
str 与 bytes 之间的转换可以用 encode 和从decode 方法。
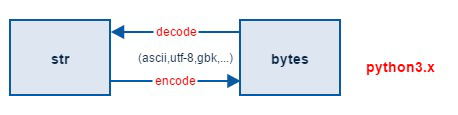
encode 负责字符到字节的编码转换。默认使用 UTF-8 编码准换。
>>> s = "Python之禅"
>>> s.encode()
b'Python\xe4\xb9\x8b\xe7\xa6\x85'
>>> s.encode("gbk")
b'Python\xd6\xae\xec\xf8'
decode 负责字节到字符的解码转换,通用使用 UTF-8 编码格式进行转换。
>>> b'Python\xe4\xb9\x8b\xe7\xa6\x85'.decode()
'Python之禅'
>>> b'Python\xd6\xae\xec\xf8'.decode("gbk")
'Python之禅'
以上就介绍了Python的相关知识,希望对Python有兴趣的朋友有所帮助。了解更多内容,请关注职坐标编程语言Python频道!
 喜欢 | 1
喜欢 | 1
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




